こんにちは!
SJC共同開発推進室の坂根です。
S3 で長期データを保管していると、コスト最適化のために Amazon S3 Intelligent-Tiering(以下、Intelligent-Tiering)を使っているというケースも多いのではないでしょうか。
アクセス頻度に応じて自動で階層を切り替えてくれるため、運用負荷も少なく、とても便利な仕組みだと思います。
そんな中、先日こんな場面に直面しました。
「半年以上前のデータを確認したい」と思い、S3 を開いたところ、オブジェクトは確かに存在しているのに、すぐに取得できない……。
対象は数万件。1件ずつ復元するのは現実的ではありません。
そんな状況を解消すべく、S3 Inventory・Athena・S3 Batch Operations を使って一括復元を試してみましたので、その方法をご紹介します。
目次
- オブジェクトを取得できなかった原因
- 概要
- 0. Intelligent-Tiering Archive 設定の無効化
- 1. S3 Inventory の有効化
- 2. Athena でアーカイブ階層を抽出
- 3. S3 Batch Operations で一括復元
- まとめ
なぜオブジェクトを取得できなかったか
Intelligent-Tiering は、オブジェクトをアクセス頻度に応じてデータを自動で階層間移動させ、コストを最適化するストレージクラスです。Intelligent-Tiering のアクセス階層は以下のとおりです。
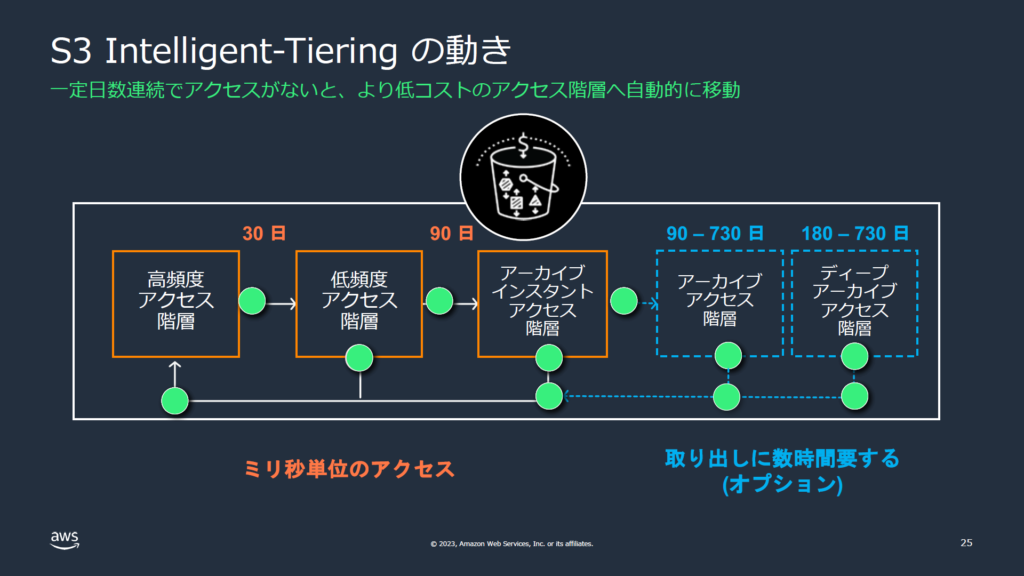
出典:AWS Black Belt Online Seminar 「Amazon Simple Storage Service (Amazon S3) コスト最適化編」 P.25
「アーカイブアクセス階層」および「ディープアーカイブアクセス階層」は、「Intelligent-Tiering Archive 設定」を有効化した場合のみ利用可能な低コスト階層です。本記事では、これら2つの階層を総称して「アーカイブ階層」と呼びます。
低コストである一方、アーカイブ階層へ移行したオブジェクトは即時取得できず、利用には復元処理が必要になります。
今回は、この「Intelligent-Tiering Archive 設定」が有効化されていたため、一部オブジェクトがアーカイブ階層へ移行しており、即時取得できない状態となっていました。
なお、図中に記載している「アーカイブインスタントアクセス階層」にも「アーカイブ」という名称が含まれますが、本記事でいう「アーカイブ階層」には含みません。
この階層は即時取得が可能であり、手動での復元処理は不要です。
概要
今回復元のために行った手順は大きく3ステップです。①S3 Inventory でバケット内のオブジェクト一覧を取得
②Athena でアーカイブ階層のオブジェクトのみを抽出
③S3 Batch Operations で一括復元を実行
全体像はこのようになります。
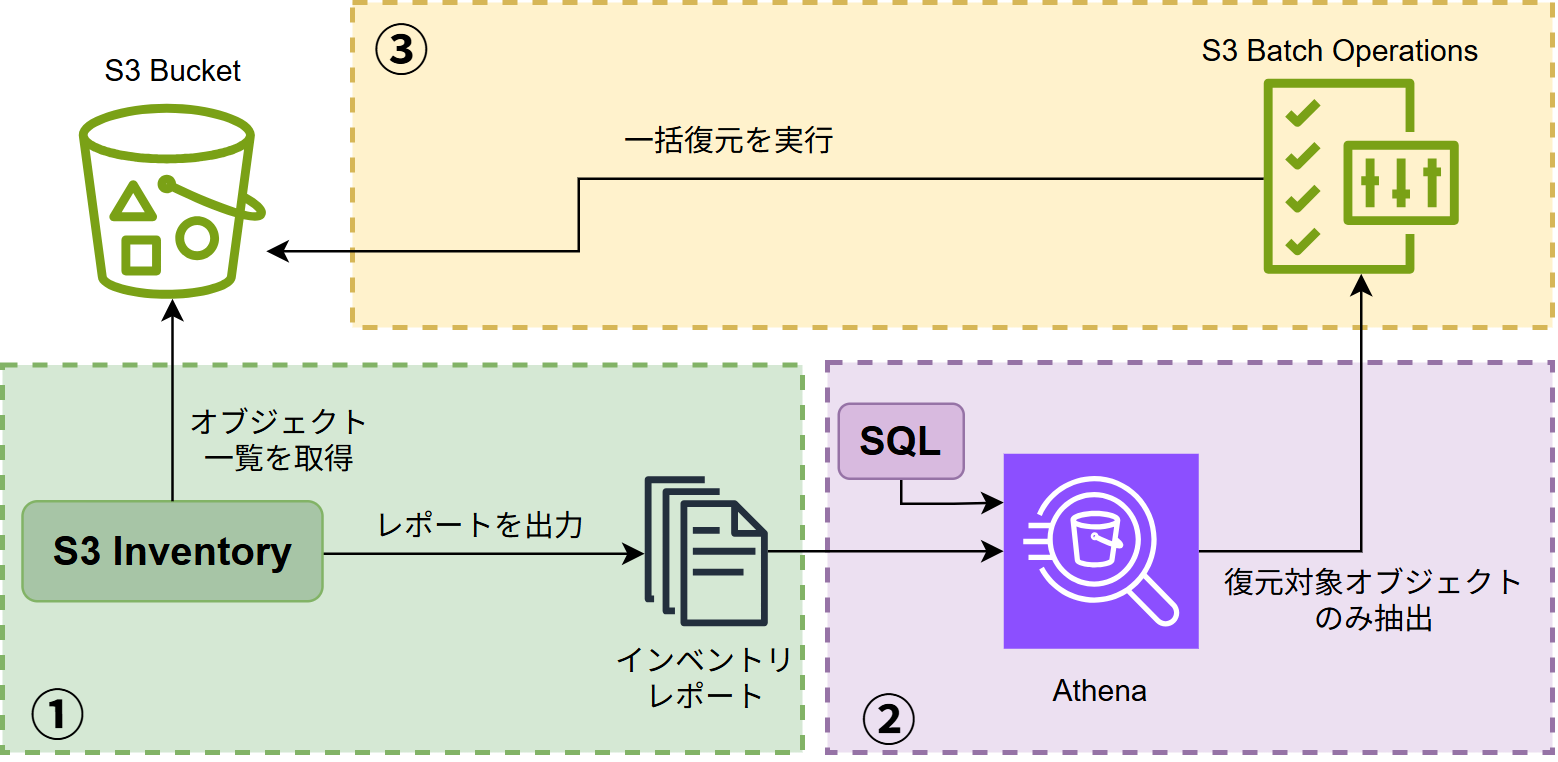
アーカイブ階層のオブジェクトは、S3 コンソールや AWS CLI からも復元可能です。
S3 コンソールで一括復元を行う場合、Intelligent-Tiering のみであれば復元操作は実行でき、復元不要なオブジェクトは自動的に除外されます。
一方で、スタンダードクラスなど異なるストレージクラスが混在している場合は、「復元を開始」自体が実行できません。
加えて、今回は対象オブジェクト数が非常に多いため、S3 Batch Operations を用いて一括復元を行います。
また、S3 Batch Operations では、復元不要や対象外のオブジェクトが含まれているとエラーとなり、失敗率が50%を超えるとジョブ自体が停止します。
そのため、本記事では事前に Athena で復元対象のみを抽出し、バッチ処理を実行する構成としています。
0. Intelligent-Tiering Archive 設定の無効化
必要に応じて、アーカイブ階層への移行オプションを無効化、または削除し、復元対象を固定します。今回は、これ以上アーカイブ階層へ移行するオブジェクトを増やしたくなかったため、事前に削除しました。 S3 コンソールから対象バケットを選択し、「プロパティ」タブを開きます。
下画像のような「Intelligent-Tiering Archive 設定」欄があるので、削除を行います。

1. S3 Inventory の有効化
S3 Inventory は、バケット内のオブジェクト一覧を定期的に出力する機能です。出力形式は CSV、ORC、Parquet から選択でき、日次または週次で生成することが可能です。
今回は、Athena で SQL による分析・抽出を行うため、CSV 形式で出力します。
CSV を選択することで、Athena との連携が容易になり、クエリによる条件抽出をスムーズに実行できます。
1-1. インベントリ設定
①対象バケットの「管理」タブを開く
②「インベントリ設定」欄で、「インベントリ設定の作成」ボタンから作成画面へ移動
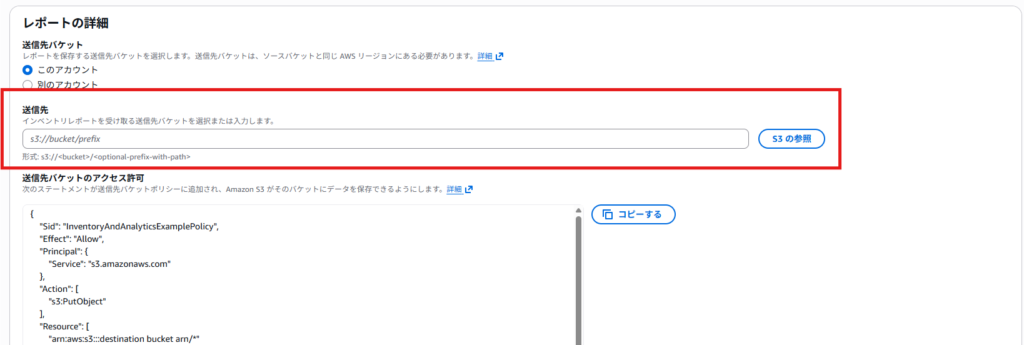
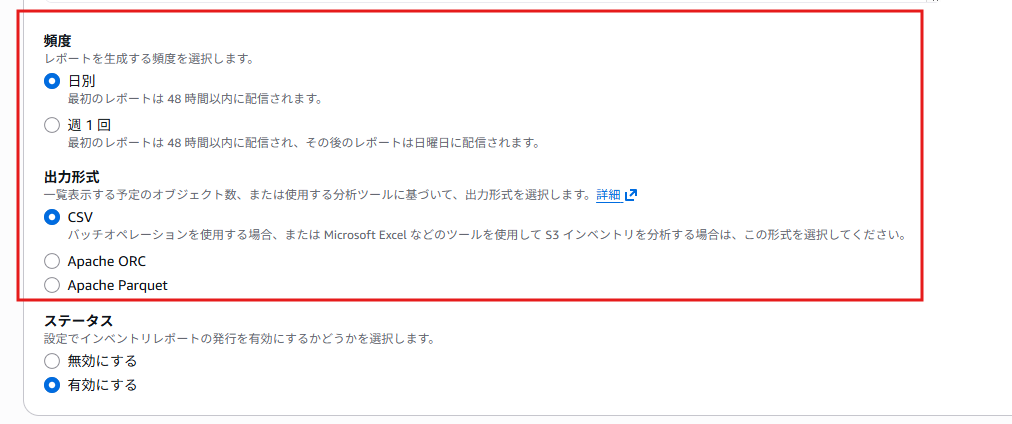
設定ポイント
- 送信先:対象のバケットと異なるバケットを指定してください
- 頻度:日別(週1回でも OK)
- 出力形式:CSV
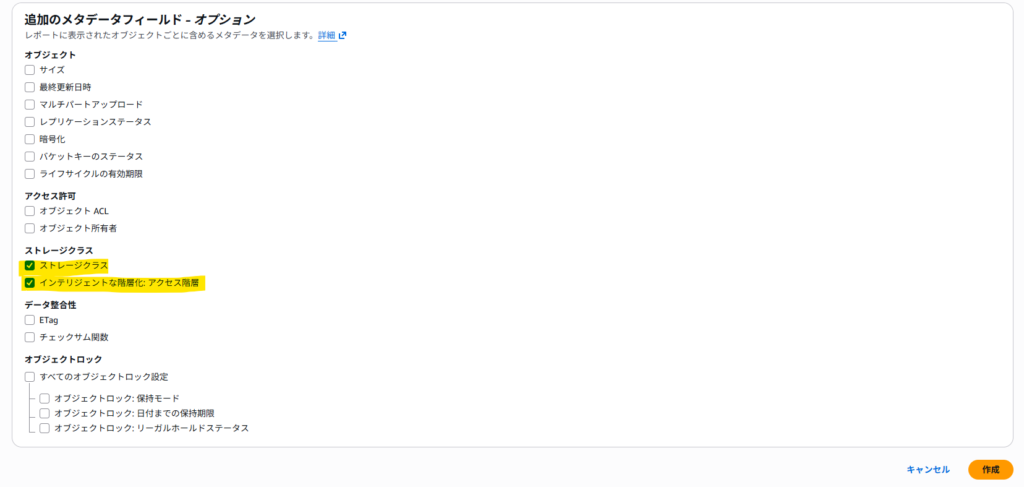
設定ポイント
- 追加フィールド:
- ストレージクラス
- インテリジェントな階層化: アクセス階層
1-2. インベントリレポートの確認
設定完了後、初回インベントリレポートは最大 48 時間以内に生成されます。その後は、設定した生成頻度(日次または週次)に基づいて自動作成されます。
レポートの作成が完了すると、設定時に指定した出力先バケットへ保存されます。
- 作成日時のフォルダ:メタ情報が記された JSON ファイル(manifest.json)
- data フォルダ:実際のオブジェクト一覧データ(.csv.gz)
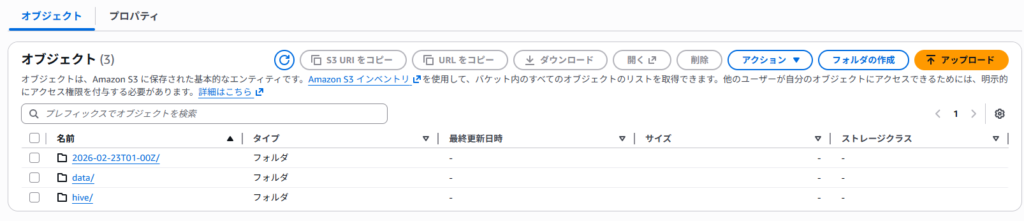
これらが確認できたら、次の手順である Athena によるデータ抽出へ進みます。
💡ポイント:manifest.json の確認
生成されたインベントリレポートの manifest.json には、レポート作成日時や対象範囲などのメタ情報が含まれています。
これを確認することで、S3 インベントリレポート生成プロセスがバケットをスキャンしはじめた時刻を把握できます。
ただし、バケット状況の反映とスキャンには時間差があるため注意が必要です。
詳細については後掲する「ポイント:インベントリレポート反映までの時間差」をご参照ください。
2. Athena でアーカイブ階層を抽出
S3 Inventory により出力されたレポートファイルを、Athena からクエリできるように設定します。Athena を利用することで、アーカイブ階層へ移行したオブジェクトのみを SQL で抽出できます。
2-1. クエリ保存先設定
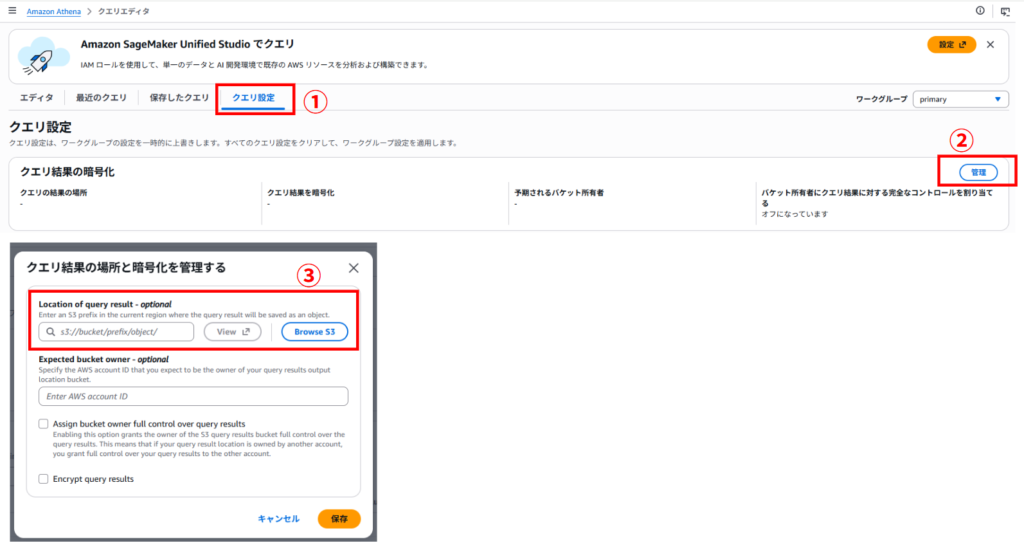
まず最初に、Athena で実行したクエリ結果の保存先を設定します。 Athena では、クエリ実行結果を S3 に保存する必要があります。保存先が未設定の場合、クエリを実行することができません。
①Athena コンソールを開き、「クエリ設定」タブをクリック
②「管理」タブをクリック
③クエリ結果の出力先を入力して保存
2-2. データベースおよびテーブルの作成
S3 Inventory により出力されたレポートは、そのままでは Athena から参照できないため、レポートの保存先を指定してテーブルを作成します。 以下の SQL を順に実行してください。① データベースの作成
sample_db というデータベースを作成します。|
1 |
CREATE DATABASE IF NOT EXISTS sample_db; |
②データベースの切り替え
sample_db に切り替えます。|
1 |
USE sample_db; |
③レポートからテーブルを作成
レポート(CSV 形式)を参照するテーブルを作成します。|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
CREATE EXTERNAL TABLE s3_object_list ( bucket STRING, key STRING, storage_class STRING, -- ストレージクラス intelligent_tiering_access_tier STRING -- アクセス階層 ) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' -- CSV 形式のファイルを正しく読み込むための設定(OpenCSV 用の SerDe を使用) WITH SERDEPROPERTIES ( 'separatorChar' = ",", -- CSV の区切り文字(カンマ) 'quoteChar' = '"', -- 値を囲む文字を指定 'escapeChar' = '\\' -- 特殊文字をエスケープするための文字を指定 ) LOCATION 's3://xxxxxxx/xxxxxxx/data/' -- レポートの保存先(data フォルダ) TBLPROPERTIES ( 'serialization.null.format'='null', -- NULL 値の扱いを定義 'compressionType'='GZIP' -- レポートが GZIP 圧縮の場合に必要 ); |
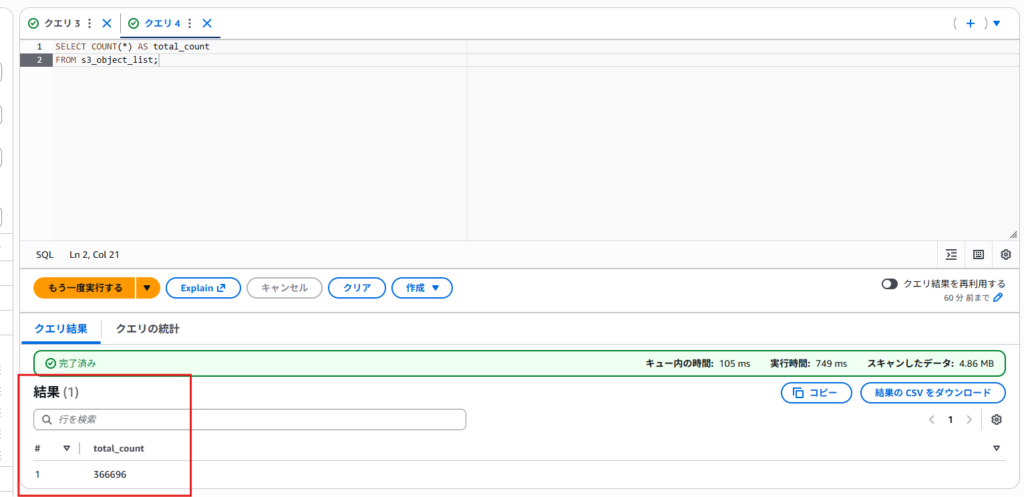
④データがテーブルへインポートされたか確認
SELECT 文で何件インポートされたか確認してみます。|
1 |
SELECT COUNT(*) AS total_count FROM s3_object_list; |
ここで0件の場合、SQL の LOCATION の指定が誤っている可能性がありますので、見直してみましょう。
2-3. アーカイブ階層を抽出
先ほど作成したテーブルから、今回抽出したいアーカイブ階層のオブジェクトを抽出し、結果を S3 へ保存します。|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
UNLOAD ( SELECT bucket, "key" -- S3 Batch Operations で必要な項目 FROM s3_object_list WHERE storage_class = 'INTELLIGENT_TIERING' -- Intelligent-Tiering のみ対象 AND ( intelligent_tiering_access_tier = 'ARCHIVE' -- アーカイブアクセス階層 OR intelligent_tiering_access_tier = 'DEEP_ARCHIVE' -- ディープアーカイブアクセス階層 ) ) TO 's3://xxxxxxx/xxxxxxx/' -- 抽出結果の出力先 WITH ( format = 'TEXTFILE', -- CSV 形式で出力 field_delimiter = ',', -- カンマ区切り compression = 'NONE' -- 圧縮なし(Batch Operations 用) ); |
2-4. 抽出結果確認
出力されたファイルには、抽出したオブジェクトのバケット名とオブジェクトキーが記載されています。ファイルには拡張子がない状態で出力されますが、ダウンロードして中身を確認すると、CSV 形式になっていることが分かります。
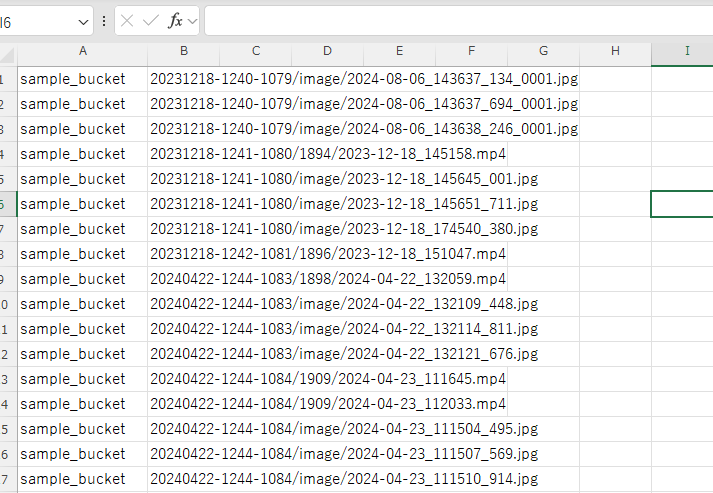
3. S3 Batch Operations で一括復元
Athena で抽出した CSV ファイルをマニフェストとして使用し、アーカイブ階層へ移行しているオブジェクトを一括復元します。3-1. IAM ロール作成
S3 Batch Operations を実行するには、Batch Operations が対象バケットへアクセスできる IAM ロールを事前に作成する必要があります。①ポリシーの作成
IAM コンソールから、「ポリシー」>「ポリシーの作成」を選択し、カスタムポリシーを作成します。■必要なアクセス権限
| バケット | 適用先(Resource) | 操作(Action) | 用途 |
|---|---|---|---|
| マニフェスト格納バケット | マニフェスト格納フォルダ内の全オブジェクト | s3:GetObject | マニフェストファイル(Athena で抽出した CSV)の読み取り |
| 実行レポート出力バケット※ | レポート出力フォルダ内の全オブジェクト | s3:PutObject | バッチ実行結果の出力 |
| 復元対象バケット | バケット全体 | s3:RestoreObject | アーカイブされたオブジェクトの復元実行 |
| 復元対象バケット | バケット全体 | s3:GetObject | オブジェクト情報取得 |
②ロール作成
IAM コンソールで「ロール」>「ロールの作成」を選択します。ロール作成画面の「信頼されたエンティティ」には S3 Batch Operations を選択します。
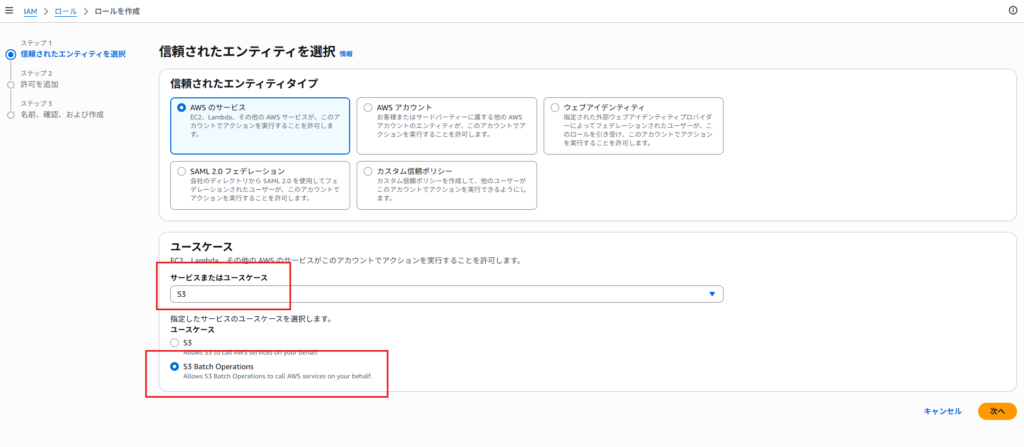
許可ポリシーには、先ほど作成したカスタムポリシーを適用して、ロールを作成します。
3-2. ジョブ作成
①S3 コンソールの左のメニューから、「ストレージ管理とインサイト」>「バッチオペレーション」と選択
②「ジョブを作成」をクリック
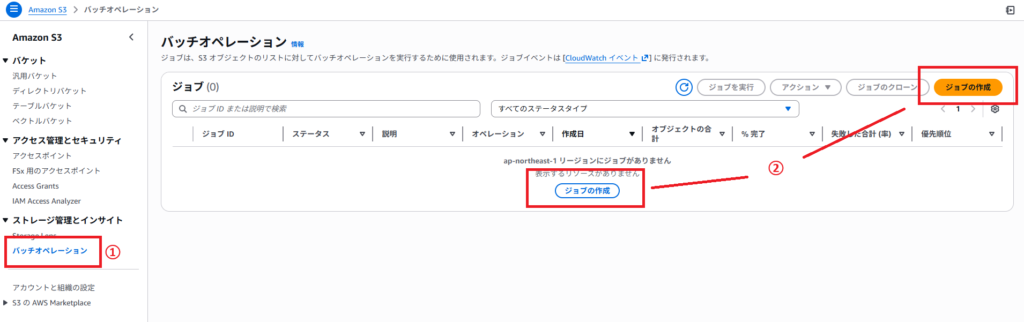
③マニフェストの指定
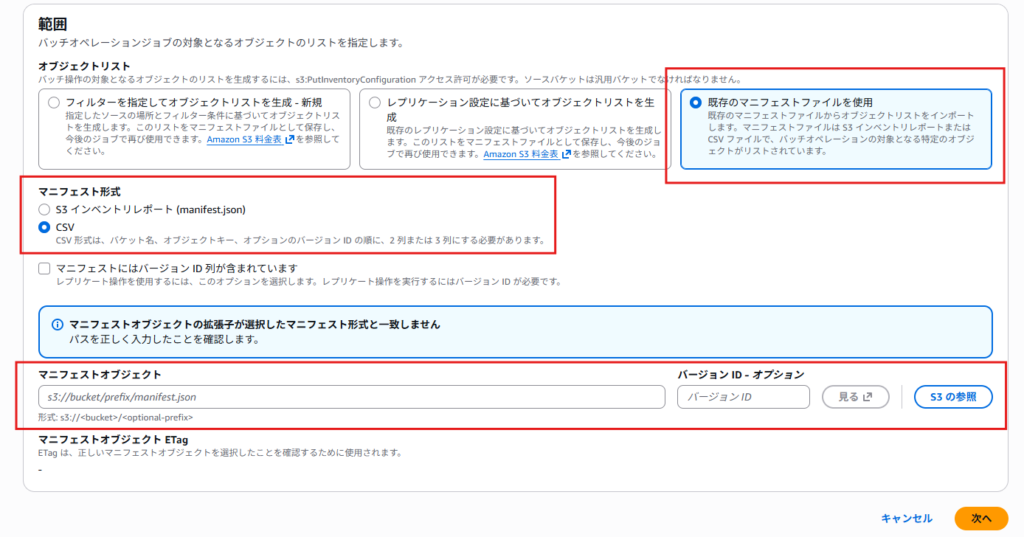
設定ポイント
オブジェクトリスト:既存のマニフェストファイルを使用
マニフェスト形式:CSV
マニフェストオブジェクト:Athena で抽出したファイルを指定
④オペレーションの選択
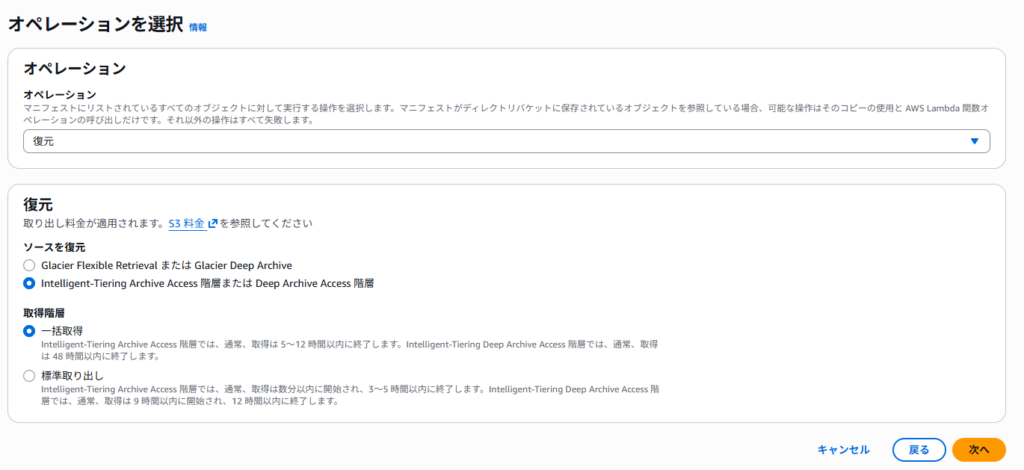
設定ポイント
オペレーション:「復元」を選択
ソースを復元:「Intelligent-Tiering Archive Access 階層または Deep Archive Access 階層」を選択
取得階層:「一括取得」or「標準取り出し」
💡ポイント:取得階層の選択について
取得階層は、復元にかかる時間を基準に選択します。
今回対象としている Intelligent-Tiering のアーカイブ階層では、復元リクエスト自体に追加料金は発生しません。
「一括取得」
目安として、アーカイブアクセス階層で約5〜12時間程度、ディープアーカイブアクセス階層では最大48時間程度かかります。
Glacier 系ではコストは抑えられるため、大量データを急がず復元する場合に適しています。 「標準取り出し」
アーカイブアクセス階層で約3〜5時間程度、ディープアーカイブアクセス階層では最大12時間程度で復元可能です。
一括取得よりも早く利用できますが、Glacier 系ではコストはやや高くなります。
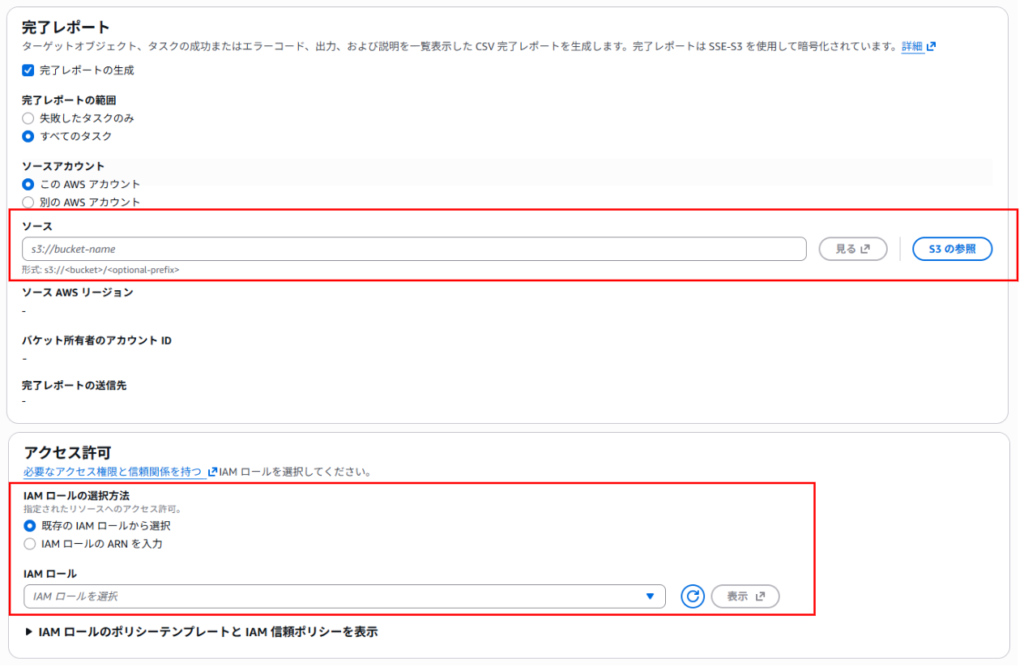
⑤追加オプション
完了レポートの出力先を指定する必要があります。「アクセス許可」には、手順3-1で作成した IAM ロールを選択してください。
3-3. ジョブ実行
作成直後のジョブは、ステータスが「準備中」の状態です。これが、「実行のための確認待ち」に変わることを確認し、「ジョブを実行」で実行します。

3-4. 実行結果確認
S3 Batch Operations による復元結果は、最新の S3 インベントリレポートと Athena で確認できます。①最新のインベントリレポートをもとにテーブルを作成
最新の S3 インベントリレポートからテーブルを作成します。手順2-2の③で使用した SQL の、LOCATION 句でのインベントリレポートの指定先を変更して使用してください。
②復元済みオブジェクトを抽出
件数を確認するだけなので、手順2-3で実行した抽出条件(WHERE 句)をそのまま流用するだけで問題ありません。クエリ実行結果が0件であれば、復元対象の全オブジェクトが復元完了していることを意味します。
|
1 2 3 4 5 6 7 8 |
SELECT COUNT(*) AS restored_count FROM s3_object_list_latest WHERE storage_class = 'INTELLIGENT_TIERING' -- Intelligent-Tiering のみ対象 AND ( intelligent_tiering_access_tier = 'ARCHIVE' -- アーカイブアクセス階層 OR intelligent_tiering_access_tier = 'DEEP_ARCHIVE' -- ディープアーカイブアクセス階層 ); |
💡ポイント:インベントリレポート反映までの時間差
復元完了後すぐのインベントリレポートには、最新の復元状況が反映されていない場合があります。
S3 Inventory のスキャン(インベントリリスト作成)の具体的な開始タイミングや所要時間は公開されておらず、スキャン開始からレポート生成時刻までの間に行われた変更は、当該レポートに反映されない可能性があります。
そのため、オブジェクトはすでに復元されていても、Athena で確認した結果が0件にならないことがあります。
特にインベントリ設定で頻度を「日別」にしている場合は、復元完了の翌々日以降のレポートで確認することを推奨します。
💡ポイント:復元後の有効期限の違い
復元後の挙動は、ストレージクラスによって大きく異なります。今回は Intelligent-Tiering のアーカイブ階層からの復元であり、手順0で「Intelligent-Tiering Archive 設定」を無効化しています。
- Intelligent-Tiering
- 復元すると高頻度アクセス階層へ戻る
- 一時コピーではない
- ただし、「Intelligent-Tiering Archive 設定」を有効化したままだと、アクセス頻度に応じて一定期間後に再びアーカイブ階層へ自動移動する
- Glacier 系(Flexible Retrieval / Deep Archive)
- 復元は、有効期限付きの一時コピー
- オリジナルはアーカイブ階層のまま
- 有効期限を過ぎると再度復元が必要
よって、復元後に有効期限が設定される心配はありません。
まとめ
今回は、S3 Inventory・Athena・S3 Batch Operations を活用してアーカイブ階層へ移行したオブジェクトを一括で効率よく復元する方法を紹介しました。インベントリレポートの生成と復元に2~3日かかるものの、対象件数が多い場合でも手作業を大幅に削減し、運用負荷を抑えながらデータ復旧が可能になります。
同じ状況になった際には是非試してみてください。 エコモットでは一緒にモノづくりをしていく仲間を随時募集しています。弊社に少しでも興味がある方はぜひ下記の採用ページをご覧ください!



