こんにちは!デバイスソフトウエア開発部の山内です。
新卒未経験で入社してから2年弱、開発に携わってきました。
設計もインフラも実装も、結局ぜんぶ「勉強」だなぁ…と日々感じています。
そんな中、一つ思っていることがあります。新人エンジニア(私含め)が業務をする上で一番大切なことって、実は公式ドキュメントをちゃんと読む習慣なんじゃないか?と。
今回はその話をしようと思います。
前半部では開発における情報源の扱い方、「そもそも論」について再考してみます。
それを踏まえ、後半部では、公式ドキュメントを読むことのメリット・読み方・生成AI(※以下、本記事では「AI」と呼びます)とどう付き合うかといった実務的なお話を展開していきます。
3行で要約
-
自分のコードの正当性を証明するには、最も信頼できる一次情報(公式ドキュメント)が不可欠。
-
ドキュメントは、正確性の担保に加え、「点」ではなく「面」での体系的な理解へと繋がる。
-
調査の入り口はAI、最終的な裏付けは公式情報で行う役割分担が、開発の速さと正確さを両立させる。
皆さんは、業務でAI使ってますか?多分使ってますよね。
なんといっても、ChatGPTやGeminiに聞けばだいたいのことは答えてくれます。
コードも書いてくれるし、説明までつけてくれる。
じゃあ、各言語やライブラリ等々の公式ドキュメントってもはや読む必要ないんじゃないですか?時間かかるし書いてあることも分かりにくいし。
否、そうはならないはずです。
…ではなぜそう言えるのか?
理由は色々考えられると思いますが、今回は「自分の書いたコードには説明責任が伴う」という切り口から説明してみます。
自分の書いたコードには説明責任がある
想像してみてください。
あなたが実装してレビューに出したとき、レビュワーにこう聞かれます。
「ここ、どういう意図でこうしてるの?」
「この書き方で大丈夫?根拠ある?」
さて、どう答えたら良いでしょうか。
「よくわからんけど動いてます!」とは、流石に言えないですね(笑)。
あなたはなぜそのコードを書いたかを説得的に説明しなければなりません。
つまり、①正確な情報から②妥当な推論をして説明しないといけないわけですね。
このとき、あなたは何を情報源として説明しますか?
- 公式ドキュメント
- ソースコード(仕様の実装そのもの)
- 技術ブログ(Qiita / Zenn 等)
- フォーラム(StackOverflow 等)
- 経験則
- AIの回答
- etc.
挙げてみた情報源を眺めてみると、上記の情報源はすべて同格というわけではない、という点に気づきます。
使う情報源の信頼性は「一次情報への近さ」によって判断できる
考えてみると、公式ドキュメントが、個人の技術ブログを参照して書かれることは考えにくいですよね。
逆に、技術ブログが公式ドキュメントを参照することはよくあります。
ここから想起できるのは、それぞれの情報源が網のように参照し合っているというよりむしろ、「情報源」の中でもより根っこに近い存在(=一次情報に近い存在)がいて、それがある程度の信頼性をもって他の情報源に利用されている…というイメージです。
最近私はSwift一辺倒なのでSwiftを例にとると、まず公式なドキュメントとしてApple Developer Documentationがあり、それを参照するか実際に自力で検証するかして技術系記事が作られます。
そしてそれらを引用する記事やフォーラムも出るし、さらにはAIがWeb上の情報をかき集めてきたりもします。
図に起こしてみると、こんな感じでしょうか?(あくまでイメージですが)
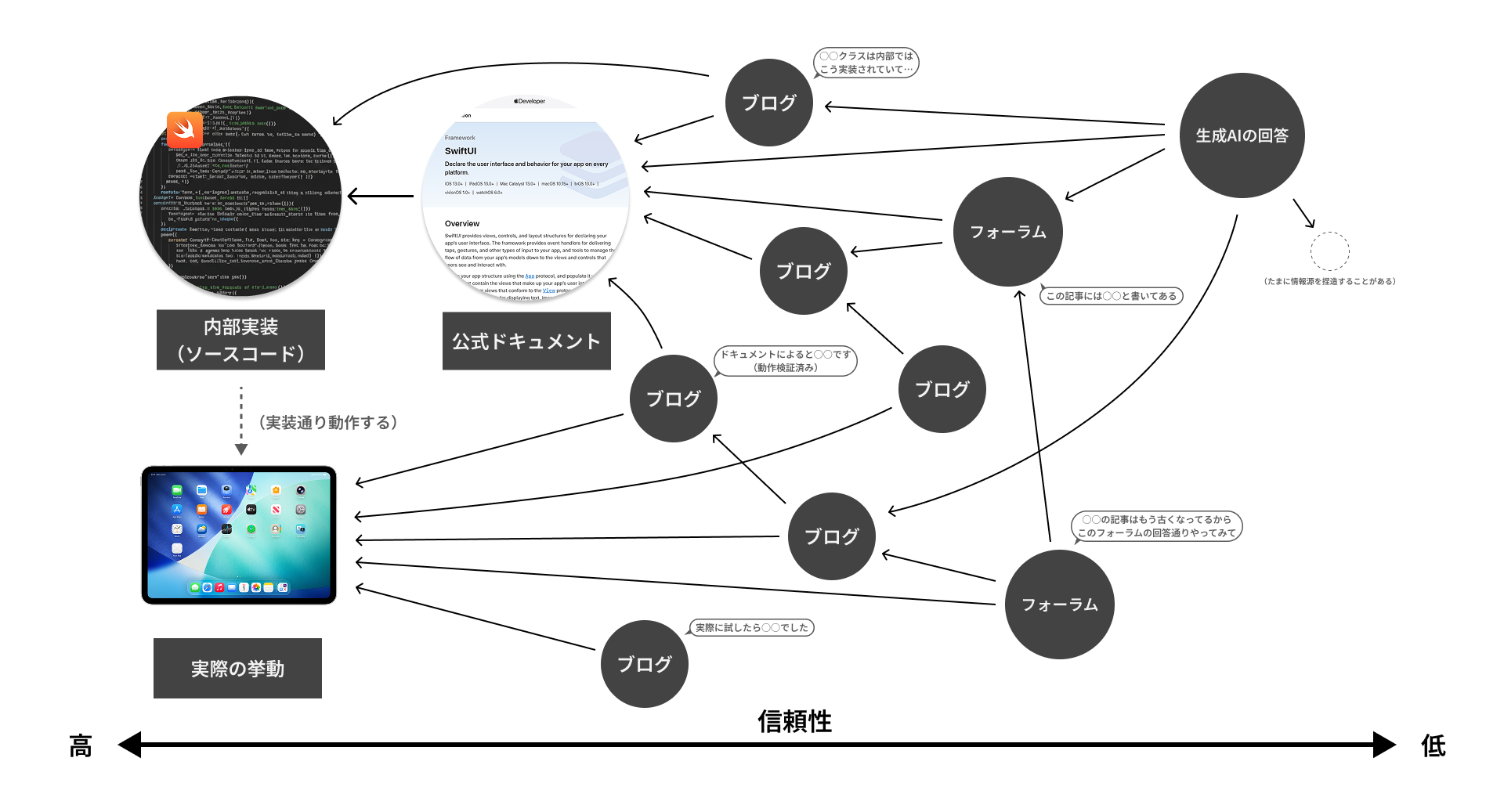
各種情報源は網のように無秩序に繋がっているように見えても、実のところ一次情報は明確に存在しておりそれらを次々と参照していく形態となっていることがわかる
このように見ると、それぞれの情報源は、「一次情報からの距離」を尺度として分類・評価できそうだということが言えます。
それはすなわち、一次情報に近いほど「根拠として強い」・「より信頼できる」=信頼性が高いということでしょう。
それはそのまま、説明力・説得力の強さに繋がります。
なぜ「信頼性」が重要なのか
では、なぜそう言えるのでしょうか?
そもそも、なぜ信頼性は重要なのでしょうか?
ちゃぶ台返しみたいな話になっちゃいますが、どんな情報であっても、実際に情報源の記述通り実装したり動作させたりして、自力で実験すれば、その情報が正しいかどうかはわかるはずですよね。自力ですべて検証できる分には、信頼性はさほど重要ではないとも言えます。
しかし実際にはそんな時間ないわけで。言語やフレームワークの内部実装を全て読んだり、Apple Developer Documentationに書かれている記述を全部自力で実装して確かめようとしたら、日が暮れるというか年が明けるというかプロジェクトが終了しちゃいますね。
つまり、受け手が毎回すべての情報を厳密に検証できるわけではないという現実がある。
だからこそ、我々は何らかの断片的な手がかりによる判断(ヒューリスティック)を駆使し、「その情報は信用できそうか」を判断することになるわけです。[1]
例えば、「誰が書いたか」「いつ書かれたか」「信頼できる書き口か」「誤字脱字は無いか」等々…。最近は「AIの文章っぽくないか」も重要かもしれません。
では、「自力で検証した情報だけでなく他者からの情報も使いますよ」となった際、リスクとなるのは何でしょうか。
「誤情報」「誤解」のリスクです。
うっかりであれ意図的であれ、情報伝達をする以上、誤った情報を伝えてしまうリスクは常に介在します。
したがって我々は、情報や話者の信頼性を見張る仕組み(epistemic vigilance: 認識的警戒)を働かせながら、受け取る情報を取捨選択している仕組みをもっていると言われています[2]。
では、具体的にどういう基準で信頼性を見張っているのかといえば、
-
能力 (Competence): 発信者が正しい情報を提供できる知識や専門性を持っているか。
-
誠実さ (Honesty): 発信者が(利害関係や悪意に左右されず)嘘をつかずに真実を伝える意志があるか。
という2つの観点が指摘されています[3]。
これらを踏まえると、言語/フレームワーク/ライブラリの開発者本人あるいは同組織の人間が書いたドキュメントが、より「信頼に足る」と判断されやすいのだと、おのずと分かってくるのではないでしょうか。
ここまでのまとめ:実装の説明で問われるのは「根拠の信頼性」
…さて、大元の「説明責任」の話に戻って考えてみると、実装の説明を求めているレビュワーにとっては、レビュイーである実装者が最も近しい情報源となります。
しかし、先ほどの観点を踏まえるなら、実装者の説明があやしかったり、経験が少ないほど、「能力」「誠実さ」は割り引かれて捉えられてしまいます。「こいつの言ってること本当か?」と。
それを補完するのが、まさしく実装者の説明が依拠する「根っこ」の情報源の信頼性です。
言語やフレームワークの開発者が公式に出しているドキュメントに基づいてあなたが説明すればこそ、あなたの説明は「信頼に足る」と判断されやすくなるのです。
というわけで、ここまで「コードの説明責任」という切り口から「情報源の信頼性」の考察を経由する形で、公式ドキュメントを読むことの重要性を考えてみました。
ここからはもうちょっと視野を広げて、そしてもうちょっと実務寄りで話を進めていきましょう。
私なりに、短い経験から公式ドキュメントを読むことのメリットを挙げるなら、
- 確かな根拠をもって実装ができるようになる
- 体系的な理解が進みやすい
という2点が大きいです。
前者はこれまでも論じた通りで、利用している言語やフレームワークの仕様に適った書き方をすることで、謎の不具合やバグも起きにくくなりますし、加えて、他の人がソースコードを読んだ時にキャッチアップしやすくなるメリットもあったりします。
後者については、例えば、毎回ググるかAIに聞きながら開発をしていたら、「1つの質問→1つの回答」というラリーになってしまいがちです。
求めた知識がピンポイントに与えられるスタイル。
他方、同じ調査でもドキュメントを漁ってみると、その周辺知識や依存関係も含めた知識がつきやすくなります。
ちょうど辞書を読んで色々な定義や隣の単語を目にするのと同様、知識が「点」ではなく「面」で得やすくなるイメージです[4]。
辞書もAPIドキュメントも、ターゲット周辺の知識を「偶発的学習」によって習得しやすいメディアと捉えられる。
公式ドキュメントの読み方
でも、正直、公式ドキュメントってしんどいですよね。
私がよく見る Apple Developer Documentation は、基本的に英語です。日本人にはつらい…。
そのほか、どの項目を見ればいいのか分からなかったり、分量が多かったり、いろいろ大変ですよね。
でも、実のところ全部読む必要はなかったりします。
まだまだ浅い経験からではありますが、今のところの個人的「傾向と対策」をご紹介します。
ドキュメントあるあるとその対策
どこに何が書いてあるかわからない
ドキュメントを初めて見たとき、しばしばそういうことがあります。
こういう時は、
- まずドキュメントや項目のトップに行き、目次を眺める
- 概要やチュートリアルを読む
このあたりから始めてみて、全体のつくりをざっくり掴むと良いです。
「チュートリアルやってる時間なんてないよ!」という方もいるかもしれませんが、ここはまさに「急がば回れ」の領域で、いきなり細部を見てもかえって理解に時間を要することはよくあります。ちょっとの辛抱です。
英語がつらい
ですよね。たまに「コンピューターとプログラミング言語が日本で発明されていればなあ」なんて思ったりしますね。
無論、「英語を使いこなせるようになる」のが最も理想的なのですが、つらかったら翻訳機能を駆使して全然構わないと思います。
ただし、大事そうなことが書いてあったら単語レベルで意味を確認する習慣をつけましょう!結構大事です。
なぜなら、その英語と意味が一致する日本語があるとは全然限らないからです。翻訳によって解釈違いが起き得るからこそ、正確な解釈にこだわるのが吉です。
実現したい仕様に合った記述がない
これも何かと発生しがち…。
要因としては、①求めている仕様が特殊なケース、②そもそもドキュメントがあまり充実していないケースがあり得ると思います。
①の場合、理論的にはドキュメントの記述を応用していけば仕様を満たす実装ができるはずですが、「いやそもそもわからんわ!」となったら、その時は手掛かりとして有志の技術ブログやフォーラム、そしてAIを使うべき時だと思います。
後述しますが、この「情報を探索する」という段階では、情報量は多いに越したことはないわけです。
ただ最終的には、やはり自分でコードを書いて検証し、最後にそれがドキュメントの仕様と整合するか確かめる…という確認作業をやっておくと良いですね。
AIとの付き合い方(私のおすすめ)
さて、このブログ、「全部AIで良くね?」みたいな問いから入っていきました。
結論としてはNOなのですが、しかしここで強調しておきたいのは、「公式ドキュメントを読むことは重要だが、他の情報源は信頼できず無用だ」と言いたいのではないということです。
どちらかと言えばむしろ「情報の探索」→「情報の検証」でうまく情報源の使い分けをしましょうねという話であって、むしろAIは調査の入口/手がかりとして相当使えるはずです。
まだ勉強を始めたばかりのエンジニアにとっては、そもそも「公式情報」がどこにどうやって蓄積されているかすらわからないケースがあります(←昔の私です!)。
分からない概念や実装したいコードがあれば、最初はAIに聞き、解決策と出典を答えてもらうようにしましょう。そうすれば、未検証ではあるけれどそれらしい回答と、あなたが調査すべき情報源が同時に手に入ります。(※ただしAIは存在しないリンクを結構提示してきたりするので、ちゃんとリンクが踏めるか検証してくれと釘を刺しておきましょう!)
というわけで、繰り返しにはなりますが、
- AIと巷のブログ・フォーラムは探索的調査のツールとして使う
- 最後は自分で検証するか公式ドキュメントで裏付けを行う
という使い分けを行うことで、情報調査の効率と正確性、ひいては自身の行った実装の根拠・説得力がより高まることでしょう!
おわりに
AIが普及した今だからこそ、最も信頼できる情報源として公式ドキュメントを読む価値が上がった気がしています。
そして、その用途はただ調べるというより、「網羅的に知る」あるいは「信頼性を高める」ためのツールへと向かっていくのかもしれません。
私自身も引き続き、日々開発を勉強しながら、情報との上手い付き合い方を模索していこうと思います。
さて、最後までお読みいただきありがとうございました!
エコモットでは一緒にモノづくりをしていく仲間を随時募集しています。弊社に少しでも興味がある方はぜひ下記の採用ページをご覧ください!
脚注
- とりわけ、情報が氾濫しているオンライン環境では、人は評判やレビュー、一貫性などといった「認知的ヒューリスティック」によって情報源を判断する傾向があると論じられています。
詳しくはこちら:
Metzger & Flanagin, 2013: Credibility and trust of information in online environments: The use of cognitive heuristics. (https://flanagin.faculty.comm.ucsb.edu/CV/Metzger%26Flanagin%2C2013%28JoP%29.pdf) - Sperber et al. 2010: Epistemic Vigilance. (https://dan.sperber.
fr/wp-content/uploads/ )EpistemicVigilance.pdf - Hovland & Weiss, 1951: The Influence of Source Credibility on Communication Effectiveness. (https://
fbaum.unc.edu/teaching/ articles/HovlandWeiss-POQ- 1951.pdf) - この「面」で知識を得るという考え自体も重要です。プログラマーがコードを修正する際の戦略を「必要に応じて修正箇所を把握するアプローチ」、「全体的な制御フローやデータ構造を網羅するアプローチ」に分類したとき、後者のプログラマーだけがプログラムの意図的な構造を理解し、正確な修正をしたという研究も存在しています。
詳しくはこちら:
Littman et al. 1987: Mental models and software maintenance. (https://www.sciencedirect.com/science/article/pii/0164121287900331)




