はじめに
画像処理は、化学、製薬、食品産業などのさまざまなプロセスを理解するために適用できる強力なツールです。画像分析は、多相システムで発生するプロセスの場合によく使用されます。 多相システムは、分散相と連続相の少なくとも 2 つの相で構成されます。 分散相は通常、連続相中に懸濁した液滴または粒子 (固相) の形で存在します。 一方、連続相は液体または気体である可能性があります。 このような多相系には、例えば、エマルジョン(別の液体中の液体の液滴)、サスペンション(液体中の固体粒子)、エアロゾル(気体中の液滴または固体粒子)などが含まれます。多相系で起こるプロセスの例としては、結晶化 (溶液からの結晶の形での化合物の沈殿)、触媒反応 (触媒が固体粒子上に配置された場合)、エマルションの作成 (2つの相互に不溶な液体)またはでんぷんの糊化などがあります。 画像解析により、多相システムの構造をより深く理解できるようになり、プロセスの最適化や強化だけでなく、プロセスのより適切な制御も可能になります。画像解析の一般的な目的は、分散相の液滴または粒子のサイズ分布を見つけることです。 それにもかかわらず、分散相の形態学的特徴 (粒子の形状など) を決定することも重要です。 物体検出用の人工知能モデルの最近の急速な開発により、検出された物体の画像を構成するピクセルを非常に正確に分離できるようになりました (画像セグメンテーション)。 これらの孤立したピクセルは、オブジェクトの形状を表すマスクを形成します。 このオブジェクトが単なる分散相 の粒子(または液滴) である場合、マスクはこの粒子のサイズと形状に関する情報を提供します。 したがって、AIモデルは産業用画像解析に有用と考えられます。 さらに、これらのモデルの使用は簡単に自動化でき、分析時間が短縮されることが期待されます。この導入の最後に、このタイプの写真は通常、似ている形状と外観を持つ同様のオブジェクトで構成されていることを言及する価値があります。 ただし、画像にはかなりの数のそれらが含まれている可能性があります。
このブログでは、データアナリティクス部フバチ・ロベルトが、固体粒子または水滴を含む画像の分析に関する文献の短いレビューを紹介します。 さらに、でんぷん顆粒写真の分析について説明します。
関連研究
近年の出版物 (表 1) は、化学業界の画像を分析するために人工知能を使用することへの関心が高まっていることを示しています。 ほとんどの場合、そのような画像の分析は、Faster R-CNN に基づいて構築されたセグメンテーション モデルである Mask R-CNN モデル (He et al., 2018) を使用して実行されたことは注目に値します。 Mask R-CNN による画像セグメンテーションは 2 つの段階で構成されます。 第 1 段階 (領域提案ネットワーク) では、候補オブジェクトの境界ボックスが提案されます。 第 2 段階では、各候補ボックスの特徴が (RoiAling 層を使用して) 抽出され、その後、分類と境界ボックス回帰の手順が続きます。 さらに、検出された各オブジェクトのクラスと境界ボックス予測を行うために、Mask R-CNN はオブジェクトのすべてのピクセルをカバーするマスクを生成します。 このマスクを使用すると、固体の粒子や液滴などのオブジェクトのサイズを推定できます。
表1. 化学業界の画像を分析の例
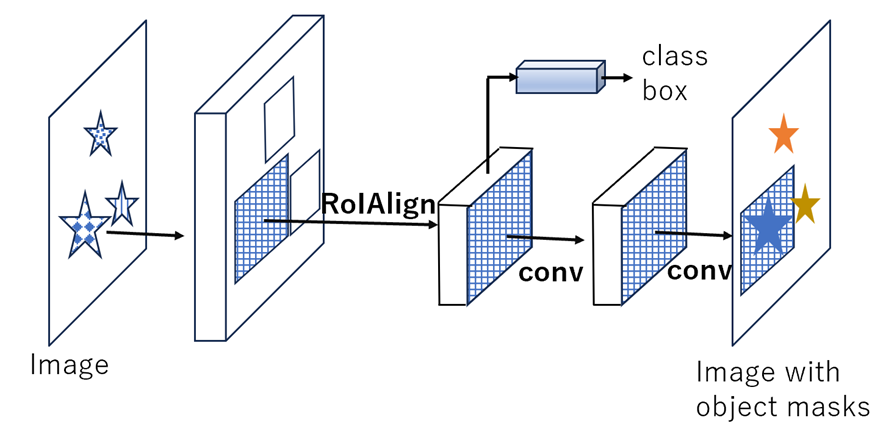
図 1. He et al. (2018)に基づくMask R-CNN フレームワーク 。
合成画像
CNN (Mask R-CNN を含む) のトレーニングには通常、大量の画像に手動でアノテーションを付ける必要があり、時間と労力がかかります。 これは、人工的に生成された写真を使用することで回避できます。 文献には、合成画像を作成するための少なくとも 2 つのアプローチが見つかります (表 1 も参照)。
1. Blender に基づく方法
Blender は、3D モデルから画像やビデオを生成するために使用できる、無料のオープンソース 3D 作成スイートです。 本物のような粒子画像を作成するための Blender 適応の例は、Frei と Kruis (2022) によって説明された synthPIC4Python ツールボックスです。 最初に、ツールボックスは、ユーザーが提供した情報、つまり粒子サイズ分布、基本形状 (例: 球形)、テクスチャ (例: 暗いまたは明るい)、および粒子変形の手順 (つまり、ランダム化可能なパラメータに基づく) を使用して、画像に必要な粒子を準備します。 . 次のステップでは、Blender の剛体物理シミュレーションを使用して、画像をより現実的にします。その後、画像のクリーン バージョンとすべての粒子のマスクが生成されます。最後のステップでは、実物のような外観が生成されます。 画像は追加の歪み(ぼかしなど)によって保証されます。
2. 敵対的生成ネットワークに基づく方法 (Vagenknecht et al. 2023)
合成粒子視覚測定 (PVM) 画像の生成にサイクル一貫性のある敵対的生成ネットワーク (Cycle-consistent Generative Adversarial Network, CycleGAN) Vagenknecht et al. (2023) を使用しました。 一方、PVMは、カメラと光源を備えたプローブを使用するその場顕微鏡技術です。 このようなプローブは、流体中に浮遊する粒子または液滴のリアルタイム画像を記録するために、プロセス装置 (化学反応器など) に挿入されます。 この PVM テクノロジーは、結晶化や乳化などの化学および製薬産業のさまざまなプロセスを理解するために不可欠です。 たとえば、粒子サイズ分布の測定や、装置内での粒子の挙動のダイナミクスの理解が可能になります。
固体粒子画像解析
分析のために、でんぷんスラリーの顕微鏡画像が選択されました。 ここで、でんぷんスラリーとは、でんぷん顆粒の水懸濁液を意味する。 画像倍率が高いため、懸濁液中の個々のでんぷん顆粒を区別することができました。 一方、このような懸濁液は食品業界のさまざまなプロセスで頻繁に使用されるため、この種の画像の分析は実用的な意味を持つ可能性があります。前に述べた、広く使用されている Mask R-CNN モデルは、画像セグメンテーションのための比較的古いアプローチです。 それどころか、昨年中に、ChatGPT4 と Segment Anything Model (SAM) という 2 つの新しい強力な AI モデルが一般に導入されました。 畳み込みニューラル ネットワークに基づくMask R-CNN モデルとは異なり、ChatGPT4 と SAM は Transformerテクノロジー に基づいて構築されました(Vaswani et al., 2017)。固体粒子を含む画像の分析の例は、He et al.(2023年)の研究にあります。 著者らは、SAM を使用したクライオ EM 顕微鏡写真からのタンパク質同定に迅速な調整アプローチを適用しました。 このブログでは、これら 2 つのモデル (ChatGPT4, SAM) をでんぷん顆粒画像の解析に応用する方法について説明します。
ChatGPT4
大規模言語モデルとして開発された ChatGPT4 は、強力なマルチモーダル ツールです。 そのため、テキストと画像の両方を理解して作成することができます。 さらに、独自に Python コードを生成し、ユーザーのプロンプトで示された目的にこのコードを使用することもできます。 このブログでは、ChatGPT4 が独自ででんぷん粒の検出にどのように対処できるかを確認します。 ChatGPT4 は GPU コンピューターにアクセスできないため、このアプローチには、たとえばハードウェアの制限があります。 したがって、強力な画像セグメンテーション モデル (Mask R-CNN など) を適用することはできません。 ただし、この章の目的は、ユーザーからのプロンプトを使用して ChatGPT4 がソリューションをどのように改善できるかを示すことです。

図 2. 一連のプロンプトによる顆粒を含む画像の分析。 Hubacz et al. (2017)らの画像。
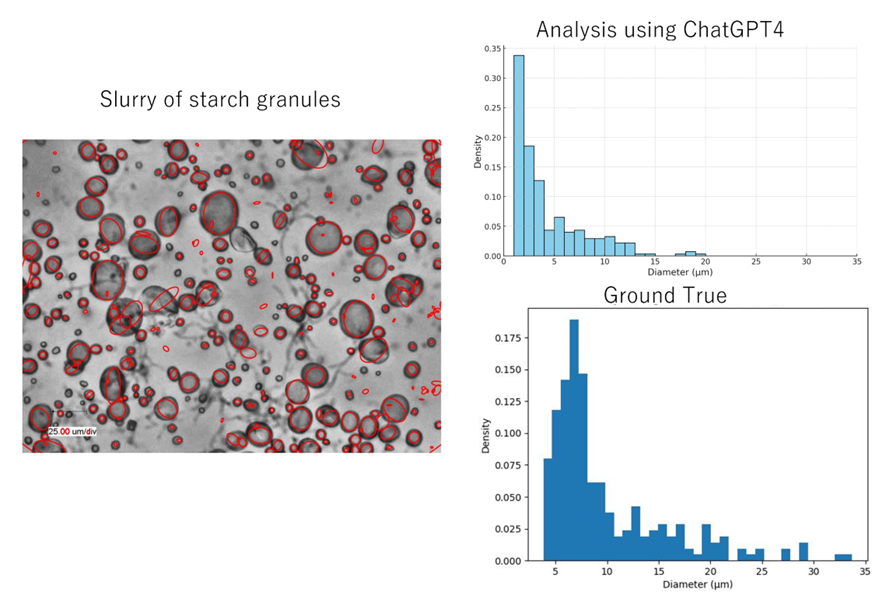
図 3. ChatGPT4 解析結果と地上実測値の比較。 グラウンドトゥルー測定の手順は (Hubacz et al.、2017) に示されています。
でんぷん粒の画像の分析は、「この写真には何が写っていますか?」という質問から始まりました。 ChatGPT4 は、これがサンプルの顕微鏡ビューであることを正しく認識し、オブジェクトのサイズを推定するために画像の下部にあるスケール (25.00 μm/div) を使用することを提案しました。 しかし、どのようなサンプルなのかは認識できませんでした。 次のステップでは、次のプロンプトが使用されました。「これらのオブジェクトのサイズ分布を推定できますか。 物体は単なるでんぷん粒です」。 ChatGPT4 は skimage (Python ライブラリ) を使用する手順を提案することで、顆粒の分布を推定することができました。 さらに、ChatGPT4 はプロンプトの形でユーザーからのフィードバックを使用して手順を最適化することができました (図 2)。 結果を図 3 に示します。予測された直径は実際の直径よりも小さく、最も小さな顆粒のいくつかは検出さえされませんでした。 これは、画像解析の応用手順が比較的単純であったことに起因する。 それにもかかわらず、前述のように、ChatGPT4 がユーザーが提供する計算プラットフォーム上のより洗練された画像セグメンテーション モデルと連携すれば、この結果はさらに改善される可能性があります。
SAM
Segment Anything Model (SAM) は、ビジョン トランスフォーマー画像セグメンテーション モデルです (Kirillov et al.、2023)。 SAM には、画像エンコーダ (事前トレーニングされた Vision Transformer ベースのマスクされたオートエンコーダ He et al., 2022)、柔軟なプロンプト エンコーダ (ポイント、ボックス、テキスト)、および高速マスク デコーダの 3 つのコンポーネントがあります。
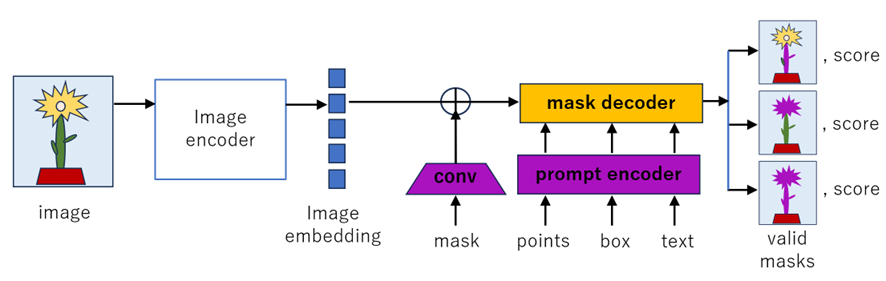
図 4. Segment Anything Model (SAM)。 図は Kirillov et al. (2023)に基づいて作成されました。
SAM はオブジェクト マスクの自動生成に使用できます。 画像内のオブジェクトを検出するために、モデルは多数のサンプル プロンプトを使用します。 これにより、複数のマスクの予測が可能になり、後でその品質に基づいてフィルタリングされます。 さらに、マスクが重複していないかどうかもチェックされます。 SAM 自動生成モードの一般的な出力は、次の項目を含む辞書です:
セグメンテーション : マスク
area : マスクの面積 (ピクセル単位)
bbox : XYWH形式のマスクの境界ボックス
predicted_iou : マスクの品質に関するモデル自身の予測
point_coords : このマスクを生成したサンプリングされた入力ポイント
status_score : マスク品質の追加の尺度
* Crop_box : XYWH 形式でこのマスクを生成するために使用される画像のトリミング
SAM の出力には、bbox や area などの興味深い追加情報が多数含まれています。 bbox は、検出されたオブジェクトの単なる境界ボックスであり、画像内のオブジェクトの位置を示します。 一方、面積はオブジェクトのサイズをピクセル単位で表します。 基準が利用可能な場合は、メートル単位に簡単に変換できます。

図 5. SAM によって生成されたでんぷん顆粒のマスク (Hubacz et al., 2017 の画像)。 左側の画像は、自動アプローチを使用して生成されたマスクを示しています。 右側の画像は、SAM によって生成された、またはユーザーによって提供された顆粒境界ボックスから生成されたマスクを示しています (自動アプローチ中に顆粒が検出されなかった場合)。
図 5 には、でんぷん顆粒の画像のセグメンテーションに対する事前学習済み SAM アプリケーションの結果が示されています。 残念ながら、ゼロショット自動生成を使用してすべての顆粒に対してマスクが生成されたわけではありません (図 5a)。 どうやら、このモデルでは顆粒のサイズが小さい場合に顆粒の検出に問題があったようです。
それにもかかわらず、SAM はプロンプト (点、ボックス、テキストの形式) を使用してオブジェクトのマスクを生成することもできます。 これらのプロンプトは、検出するオブジェクトを指定する単なるヒントです。 特に、ボックスのプロンプトには、オブジェクトがどこにあるかが正確に表示されます。 したがって、プロンプト モードで SAM を適用すると、セグメンテーションの結果が向上するはずです。 オブジェクトのセグメンテーションのためのプロンプトの準備にはかなり時間がかかります。 それにもかかわらず、自動マスク生成中に、SAM は検出された顆粒の境界ボックス (bbox) を出力します。これはボックス プロンプトに簡単に変換できます。 これにより、自動生成中に検出されなかった小さな顆粒に対してのみプロンプトを手動で準備する必要があったため、時間を節約できました。 その結果、プロンプトモードで動作するSAMによりでんぷん粒による画像のセグメンテーションを行うことができました。 図 5b は、ボックス プロンプトが使用されたときにほとんどの顆粒のマスクが生成されたことを示しています。 したがって、プロンプトを適用すると、SAM のパフォーマンスが大幅に向上すると言えます。
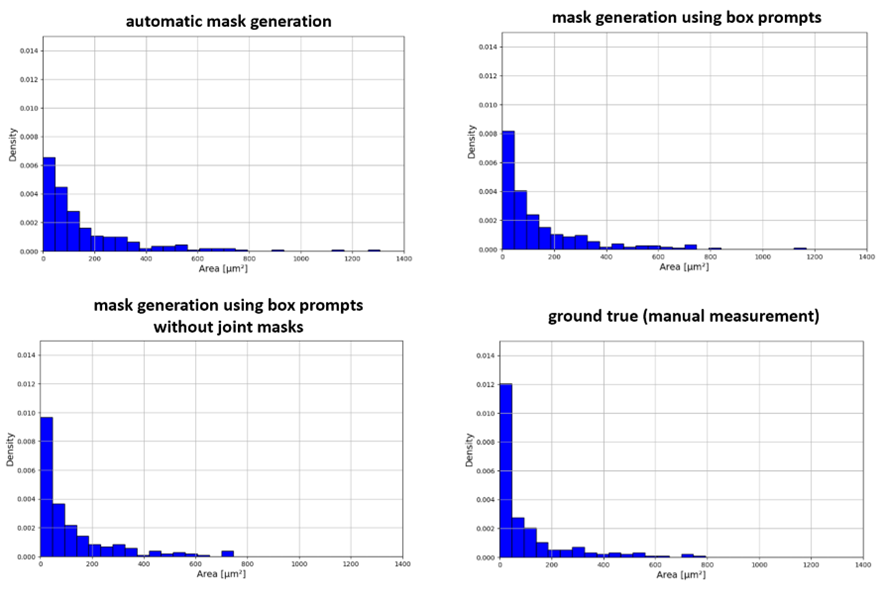
図 6. SAM によって推定された顆粒面積と手動測定の比較 (Hubacz et al.、2017)。 800µm2を超える領域はSAM間違いです。 これらの間違いは、モデルが 2 つまたは 3 つの顆粒に対してジョイント マスクを作成する場合があるという事実から生じます。 これは、いくつかの顆粒の結合マスクが各顆粒の適切に認識されたマスクで覆われているため、マスク付きの画像では確認できません。
SAM によって推定された顆粒面積と手動地上真測定 (Hubacz et al.、2017) の比較を図 6 に示します。見てわかるように、SAM 予測では、より大きな顆粒に向かって少しシフトしたヒストグラムが生成されます。 これは、ゼロショット自動検出中に小さな粒子を認識することが難しいことが部分的に原因となります。 顆粒サイズの推定誤差のもう 1 つの理由は、SAM によって生成されるジョイント マスクに関連しています。 いくつかの顆粒 (2 つまたは 3 つ) をカバーするこれらのマスクは、個々の顆粒に対して適切に予測されたマスクによって隠されるため、画像内で認識するのが困難です。 ジョイント マスクの問題は、おそらく SAM がゼロ ショット アプローチで機能したという事実に起因します。 さらに、自動マスク生成中に作成された bbox は、後でボックス プロンプトとして再利用されました。 bbox は適用されたボックス プロンプトの一部にすぎませんが、プロンプト モードで動作する SAM の予測中にジョイント マスクの問題も発生しました。 したがって、プロンプト品質の改善 (例: すべてのボックス プロンプトの手動準備)、または SAM の微調整により、不正確なグラニュール マスクの発生が減ることが期待されます。
SAM の微調整
SAM で生成されたマスクの品質は、タスク固有のイメージを使用してモデルを微調整することで向上できます。 このようなアプローチの例としては、MedSAM モデルが挙げられます (Ma et al. 2023)。 MedSAM は、医療画像の大きなデータセットを使用して事前学習された SAM を修正することによって作成されました。 それにもかかわらず、タスク固有のアプリケーション向けに SAM を微調整するには、通常、モデルの重みを大幅に調整し、高価な計算リソースが必要になります。 この問題に対処するために、Jia et al. (2022) ビジュアル プロンプト チューニング手法を導入しました。 この方法論は、事前トレーニングされたモデルの重みを変更する代わりに、タスク固有の学習可能なプロンプトを使用することを提案しました。 そのため、完全な微調整に匹敵するパフォーマンスは、少量のモデル パラメーターのみをトレーニングするだけで達成できます。 固体粒子を含む画像の分析の場合、プロンプトベースの学習は、たとえば He et al.(2023年)によって適用されました。 著者らは、cryo-EM顕微鏡写真からタンパク質を同定した。
SAM アプリケーション用のプロンプトの自動生成
前述したように、SAM によるオブジェクトのセグメント化のためのプロンプトの準備にはかなり時間がかかります。 ただし、検出されたオブジェクトを表す境界ボックスの生成にオブジェクト検出モデルを使用すると、このプロセスを高速化できます。 これらの境界ボックスは、ボックス プロンプトとして SAM に渡すことができます。 このようなアプローチの例は、Language Segment-Anything です (この例へのリンクは以下に示されています)。 Language Segment-Anything は、プロンプト生成に GroundingDINO (Liu et al., 2023) モデルを使用します。 GroundingDINO は、AI による物体検出のための最先端のアプローチです。 ユーザーのテキスト プロンプトによって提供される情報に基づいてオブジェクトを検出します。 このモデルに適用されるテキスト エンコーダーは、ChatGPT4 のような大規模な言語モデルよりもはるかに複雑ではありません。 ただし、形状が比較的単純で互いに類似した顆粒を検出する場合には、これは問題にはならないようです。 でんぷん顆粒による画像のセグメンテーションに対する事前学習済み言語セグメント何でもモデルのゼロショット アプリケーションを図 7 に示します。自動 SAM アプローチの場合と同様、境界ボックスは大きな顆粒に対してのみ見つかりました。 さらに、テキスト プロンプトの変更やモデル パラメーターの調整の後でも、結果は大幅に改善されませんでした。 このことから、画像内のでんぷん粒を検出するには、同様のデータに基づいてモデルを微調整する必要があるという結論につながります。

図 7. でんぷん顆粒の境界ボックスのゼロショットグラウンディング DINO (言語セグメント何でもコードを使用) 予測 (Hubacz et al.、2017 の画像)。 大きな顆粒のボックスは正しく検出されますが、小さな顆粒は検出されません。 モデル パラメーターを修正した後でも (box_threshold の値を下げるなど)、モデルは小さな粒子を検出できませんでした。
文献の中には、著者が迅速なプロンプト生成のための他のアプローチを研究している論文も見つかります。 その例の 1 つは、プロンプト生成の自動および対話型の方法を組み合わせた AI-SAM (Automatic and Interactive Segment Anything Model) です (Pan et al., 2023)。 そのモジュール AI-Prompterは画像を分析し、セグメンテーションの対象となる可能性が高い関心領域を特定します。 この分析に基づいて、初期点プロンプトが生成されます。 ただし、手順の詳細は著者によって提供されていません。 さらに、AI プロンプター モジュールは、生成されたプロンプトの品質を検査し、追加のユーザー入力を受け入れることができます。
まとめ
ChatGPT4 の例で示したように、現在、言語モデルの開発は非常に進んでおり、自然言語のコマンド (テキスト プロンプト) を使用して画像を分析することがすでに可能です。 原則として、この目的にはソフトウェア言語に関する高度な知識は必要ありません。ただし、画像を分析するこのような対話型の方法は、画像の数がそれほど多くない場合に可能です。 それ以外の場合は、人間の参加なしで (または人間の参加を限定して) 分析を自動的に実行する方がよいでしょう。 物体検出および画像セグメンテーションの現在のモデルでは、これらのモデルに追加の調整を行わなくても、液滴や固体粒子を検出できます (ゼロ ショット アプローチ )。 ただし、この場合、一部の誤検出や未検出が避けられません。 それは、それらのモデルがそのような目的のために訓練されていないという事実に由来します。 したがって、検出エラーを回避するには、モデルを微調整する必要があります。 ただし、微調整には、新しいタスク固有のデータセット (水滴や固体粒子を含む画像など) を準備する必要があります。 これはかなり時間と労力がかかります。 これを回避する方法の 1 つは、アノテーション (画像内のオブジェクトのマスクまたは境界ボックス) を使用して合成データセットを生成することです。 上記の観察を考慮すると、でんぷん粒を含む画像の解析は次のように行うことができます。 ステップ 1. 合成でんぷん顆粒画像の準備。 ステップ 2: 合成データベースを使用して、物体検出モデル (Grounding DINO など) を微調整します。 ステップ 3: 微調整されたモデルを適用して実際のでんぷん画像の境界ボックスを生成する。 ステップ 4: SAMは、ボックスのプロンプトとして境界ボックスを使用して、でんぷんの画像をセグメンテーションします。
参考文献
論文:
Frei M. and Kruis F. E.(2020): Image-based size analysis of agglomerated and partially sintered particles via convolutional neural networks; Powder Technology, 360
Frei M. and Kruis F. E. (2021): FibeR-CNN: Expanding Mask R-CNN to improve image-based fiber analysis, Powder Technology, 377
Frei M. and Kruis F. E. (2022) : Image-Based Analysis of Dense Particle Mixtures via Mask R-CNN, Eng 3
He K., Gkioxari G., Dollar P, Girshick R. (2018): Mask R-CNN, arXiv:1703.06870v3
He K., Chen X., Xie S., Li Y., Dollar P., and Girshick R.(2022): Masked autoencoders are scalable vision learners. CVPR, 2022. 5
He F., Yang Z., Gao M., Poudel B., Dhas N. S. E. S., Gyawali R., Dhakal A., Cheng J., Xu D. (2023): Adapting Segment Anything Model (SAM) through Prompt-based Learning for Enhanced Protein Identification in Cryo-EM Micrographs, arXiv:2311.16140
Höving S., Neuendorf L., Betting T. and Kockmann N. (2023): Determination of Particle Size Distributions of Bulk Samples Using Micro-Computed Tomography and Artificial Intelligence, Materials 16, 1002
Hubacz R., Hayato Masuda H., Takafumi Horie T., Naoto Ohmura N. (2017): Thermal treatment of starch slurry in Couette-Taylor flow apparatus, Chemical and Process Engineering 38 (3), 345-361
Jia M., Tang L, Chen B.-Ch., Cardie C., Belongie S., Hariharan B., Lim S.-N.: Visual Prompt Tuning, arXiv:2203.12119
Kirillov A., Mintun E., Ravi N., Mao H., Rolland Ch., Gustafson L., Xiao T., Whitehead S., Berg A. C., Lo W.-Y., Dollár P., Girshick R.(2023): Segment Anything, arXiv:2304.02643v1
Liu S., Zeng Z., Ren T., Li F., Zhang H., Yang J., Li Ch., Yang J., Su H., Zhu J., Zhang L. (2023): Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection, arXiv:2303.05499
Ma J., He Y., Li F., Han L., You Ch., Wang B. (2023): “Segment anything in medical images.” arXiv:2304.12306
Pan Y., Zhang S., Gernand A. D., Goldstein J. A., Wang J. Z. (2023): AI-SAM: Automatic and Interactive Segment Anything Model, arXiv:2312.03119v1
Vagenknecht M., Soukup J., Chen A., Irizarry R. (2023): A deep learning solution for particle size analysis in low resolution inline microscopy images based on generative adversarial network; Powder Technology, vol. 426
Vaswani A., Shazeer N., Parmar N., Uszkoreit J., Jones L., Gomez A. N., Kaiser L., Polosukhin I. (2017): Attention Is All You Need, arXiv:1706.03762
Wu Y., Lin M., Rohani S. (2020): Particle characterization with on-line imaging and neural network image analysis, Chemical Engineering Research and Design, 157
Yang D., Wang X., Zhang H., Yin Z., Su D., Xu J. (2021) : A Mask R-CNN based particle identification for quantitative shape evaluation of granular materials, Powder Technology, 392
ウェブサイト:
AI-SAM (Pan et al., 2023): https://github.com/ymp5078/AI-SAM
Language Segment-Anything (L. Medeiros’ Github): https://github.com/luca-medeiros/lang-segment-anything
synthPIC4Python (Frei and Kruis, 2022)): https://github.com/maxfrei750/synthPIC4Python/tree/master/primitives
blender: https://www.blender.org/
Prompt_sam_cryoPPP (He et al.2023): https://github.com/yangyang-69/Prompt_sam_cryoPPP
SAM (Kirillov et al., 2023): https://github.com/facebookresearch/segment-anything





